
Growth Marketing Data Optimization and activation
As advertisers and agencies evolve into Growth Marketing and data optimization-driven marketing programs, the RXA team (RXA.IO) helps deliver to the expectation of performance optimization, accountability, and demonstrable financial benefits through; SaaS or custom, data driven and channel agnostic Media Mix Modeling (MMM) analysis.
Media Mix Modeling Objectives
The primary objective of a media mix modeling (MMM) analysis is to estimate the return on marketing investment across various media channels. In order to achieve this, one must create a model which best captures the true manner by which the promotional activities in question impacted sales. When designing the MMM study, the structure of the historical data should be considered to select an appropriate statistical modeling technique. In my most recent client’s case, there is a nested geographical data structure ranging from country (whereby all data for a given country would be pooled during model training), to region, and lastly to subregion.
Therefore, the first task in study design is to decide how to best account for the nested data structure. This can be tricky because at too high a level of aggregation, (country, for example), meaningful nuances in the data between smaller geo-grains may be overlooked, thus misrepresenting the true impact of marketing activities on sales. Contrarily, if the data is analyzed at the subregional level, the model may pick up too much noise and arbitrary variance in the data, resulting in an overfitted model which doesn’t extrapolate validly when making new predictions.
For our client’s analyses, RXA’s Data Science Team made the decision to aggregate to the regional level, a level where the model wouldn’t overfit and the true relationships between marketing and sales wouldn’t be missed from over-pooling the data (Simpson’s Paradox).
The impact of Fixed and Random Effects
However, there is still an important decision to be made before a model is finalized, and this has to do with the nature of fixed effects and random effects in econometric modeling. Fixed effects are the impacts of the variables you’re interested in deciphering in your model, for instance, the impact of emails, face-to-face visits, or events on sales. Random effects can be thought of as control variables, factors such as geographic location which can impact sales and must be accounted for, yet are not malleable from a marketing mix perspective.
From a mathematical standpoint, incorporating region into the random effects allows for the promotional activities in each region to have a distinct intercept term. Therefore, any inherent discrepancies in sales potential between areas will be accounted for prior to estimating the impact of the marketing activities. This is what’s known as a ‘Random Intercept Model.’ In this model type, the impact of marketing activities on sales are fixed, but the intercept varies between regions.
An alternative approach is to incorporate both marketing activities and region into the random effects term, allowing both the sales potential by area and the impact of marketing activities to vary between regions. This is called a ‘Random Slope, Random Intercept Model.’ From an econometric vantage point, this model type is the most intuitive and the most likely to capture the true process by which the historical data was generated.
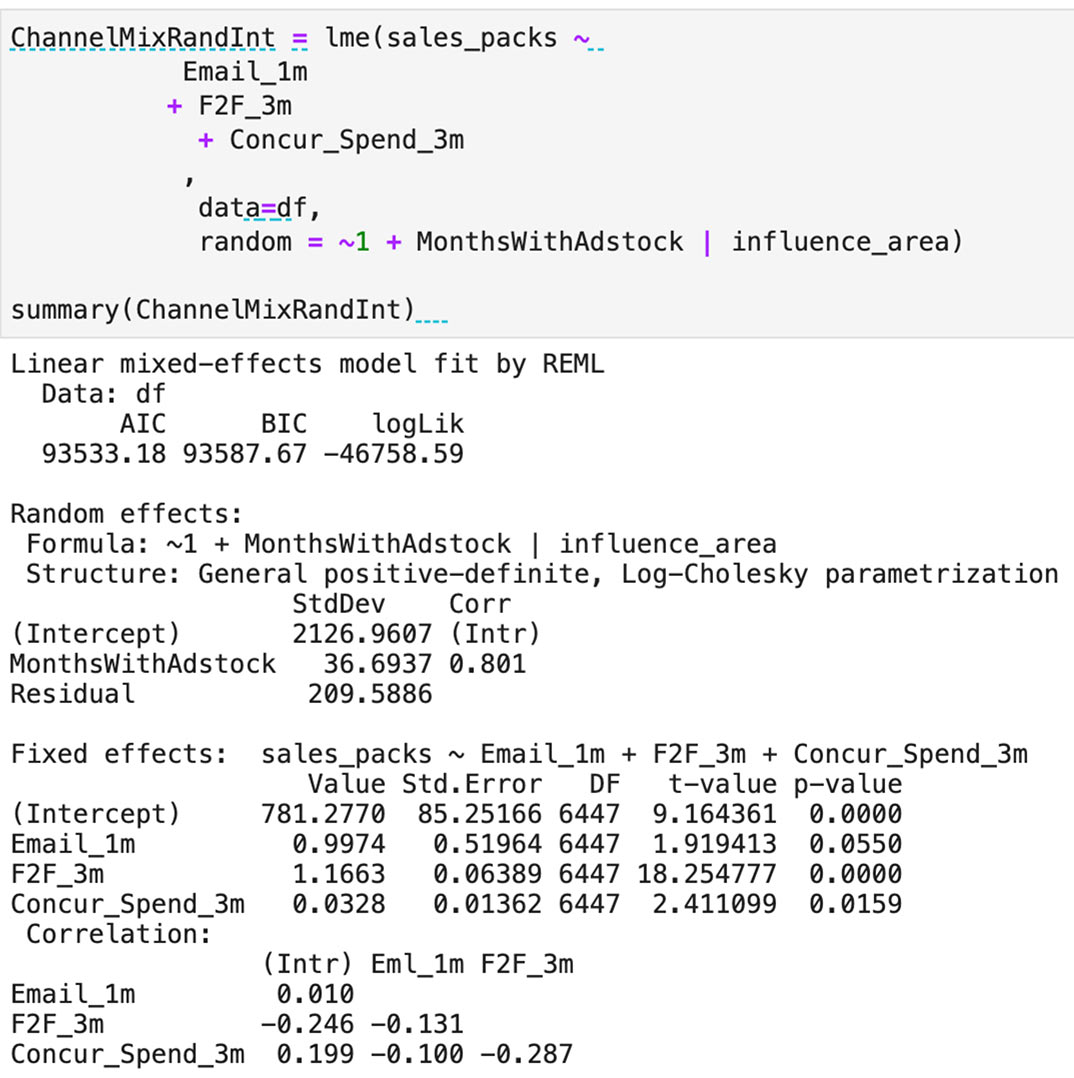
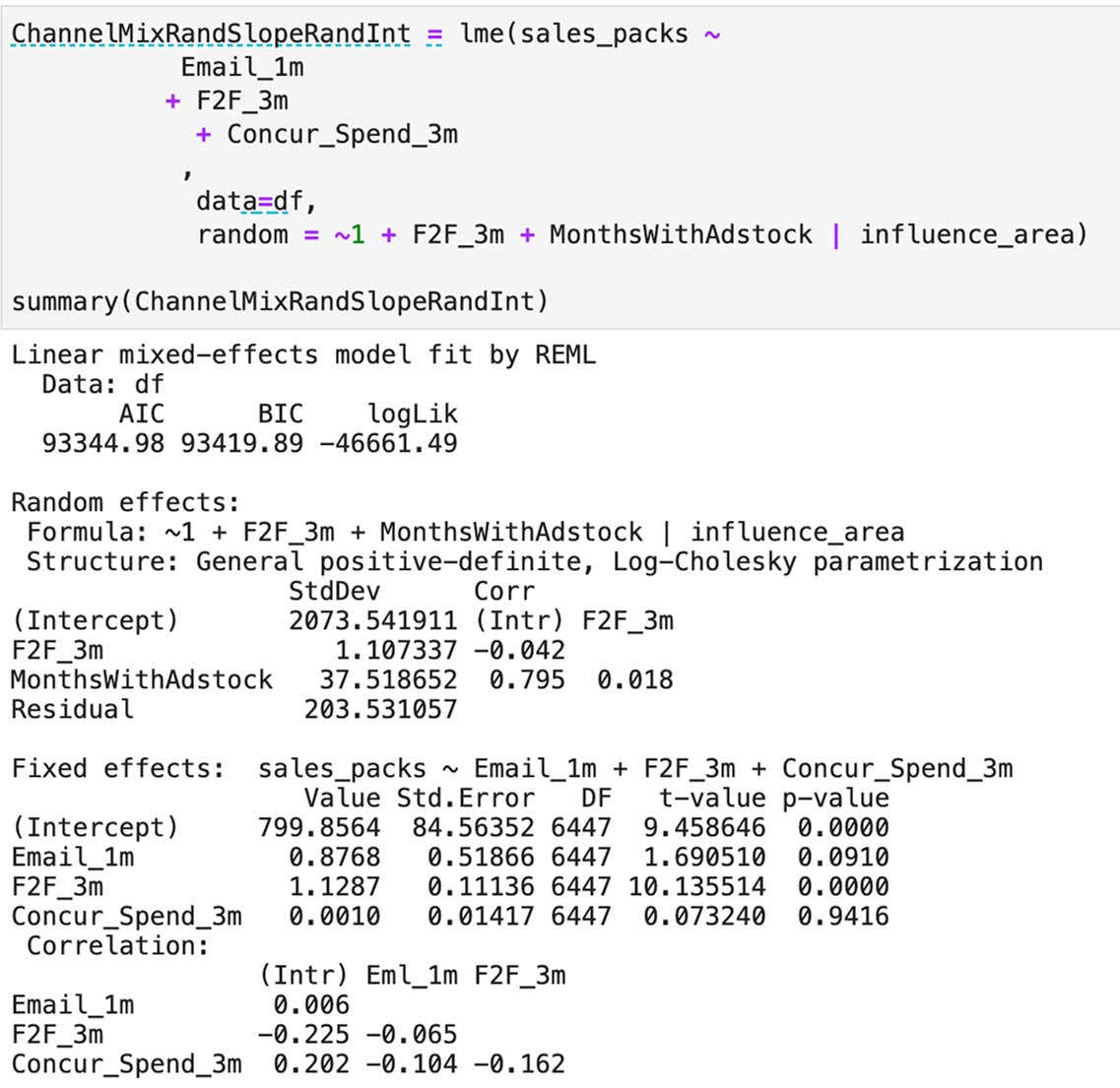
Therefore, when AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) (two metrics for assessing a model’s goodness of fit) both showed marked improvements when modeling the historical sales data with the ‘Random Slope, Random Intercept’ technique (opposed to only ‘Random Intercept’), it checks out intuitively with common econometric practice. Please refer to the outputs below for comparison. (Note: the dependent variable has been scaled using an adjustment factor to respect client privacy).
Random Intercept Model Summary:
Random Slope, Random Intercept Model Summary:
AUTHOR: Harrison Kane
Harrison Kane is a Data Scientist at RXA, a Growth Marketing Technology company fueled by data science and applied artificial intelligence. Through our GMI (Growth Marketing Intelligence) platform and solutions; RXA helps attract, convert, retain, and grow the value of our client’s customers by isolating specific business problems and developing actionable data-driven AI solutions to achieve prescribed results. Our Media Mix Modeling and Multi-touch attribution solutions are agnostic to mediums and channels to provide clients with an unbiased view of performance and optimization recommendations. You can learn more about RXA’s Growth Marketing Technology solutions by visiting us at RXA.IO or learn@rxa.com. While RXA is agnostic to BI platforms, they have been recognized as Domo’s most influential partner for 2021 and have been named Domo’s Innovation partner of the year for the past two years.